
【犀语课堂】神仙打架之三大预训练模型:GPT、盘古、悟道

Bert是基于attention机制的两阶段模型,首先是语言模型预训练;其次是Fine-Tuning模式解决下游任务。这种两阶段模型,渐渐地成为NLP领域和工业应用领域的流行方法;然而,对于Bert模型而言,一方面该模型对于领域内有标签数据过渡依赖,即使有了预训练和精调两段模式的加持,仍少不了一定量的领域标注数据,否则取得的效果仍不理想,标注数据成本也高昂;另一方面,对于领域数据分布较少时容易过拟合,即在精调阶段,当领域数据有限时,模型只能拟合训练数据分布较多的情况,如果数据较少的话,就可能造成过拟合,致使模型的泛化能力下降。
正是由于Bert存在这两方面的不足,OpenAI提出了GPT-3模型,GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
什么是GPT-3?
GPT-3是在2020年,OpenAI斥巨资打造的自然语言处理模型,GPT-3把模型参数规模增大到1750亿,并且使用45TB的数据进行训练,采用单向语言模型训练方式,一时成为了NLP领域最强的AI 模型。该模型不仅能够在问答、文本生成、翻译领域表现出色,而且在代码生成、数学推理、数据分析、图表绘制,甚至游戏畅玩领域都有不俗表现。
GPT-3的性能达到这样的高度,一方面是其庞大的参数量,达到了1750亿,是同系列GPT-2的116倍;另一方面是拥有大量的训练数据,且训练数据涵盖范围广泛,包括各种百科、数字化书籍、各种WEB链接等。显然,这些数据集囊括的文本类型丰富,包括新闻、诗歌、宗教、科学、生活、小说等,即目前人类所能涉及到的所有知识,均在其训练数据的范围之内。正是基于庞大的知识库,才能将GPT-3训练为一个“全才”。
为了方便对比,这里罗列出了GPT、GPT-2、GPT-3的参数量和预训练数据量。
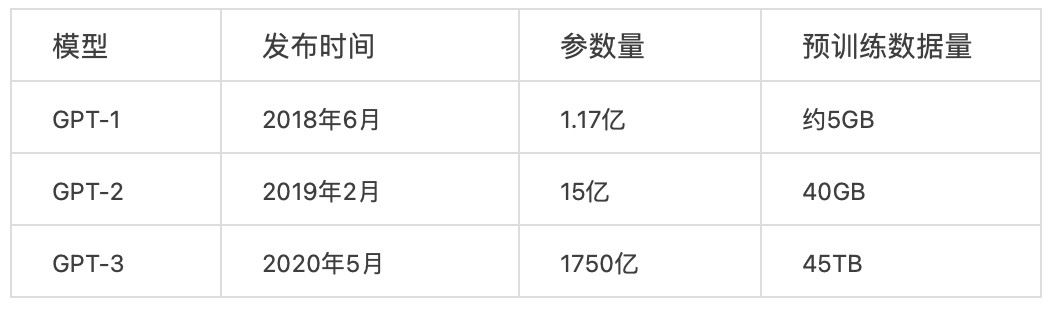
在初步了解参数量和数据量之后,我们来进一步阐述GPT-1,GPT-2, GPT-3模型的性能。
GPT-1性能
在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。GPT-1的泛化能力相对较强,能够用到和有监督任务无关的其它NLP任务中。GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
以自然语言推理任务为例,采用GPT-1预训练模型,在以下六个数据集中,有五个达到SOTA。如下图:
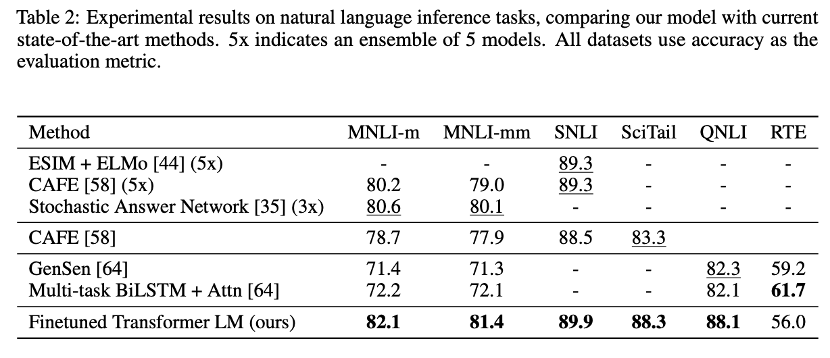
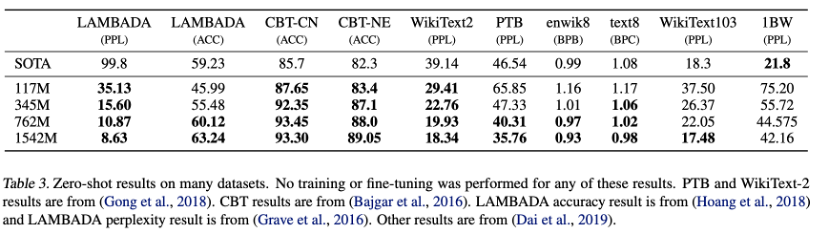 论文:Language models are unsupervised multitask learners
论文:Language models are unsupervised multitask learners
论文链接:
https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
GPT-3性能
首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。GPT-3和GPT-2相比,本质上并无太大差异,只是在数据量和参数量两个方面扩大了100倍,便获得了远超GPT-2的性能。
下面用一个简单例子加以说明,这是GPT-3模型在TriviaQA数据集上的实验结果,从中看出在TriviaQA数据集上最大的GPT-3仅使用一条样本的One-shot就已经和最好效果的微调模型效果相当,使用64条样本的Few-shot的模型效果已经超越了最好效果的微调模型,这足以说明GPT-3模型的强大。


什么是“盘古”
2021年4月25日,由华为云与其它合作伙伴鹏程实验室等联合开发的千亿参数、40TB训练数据的(NLP)预训练模型,鹏程实验室训练出业界首个2000亿超大参数中文预训练模型“盘古”。
性能方面,在零样本学习任务、单样本学习任务、小样本学习任务中均有优良表现。盘古NLP大模型在权威的中文语言理解评测基准CLUE榜单中,总成绩及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录。通过研究对比了智源研究院发布的首个26亿参数的中文预训练语言模型悟道文源,即CPM,(文章下一部分会有介绍),在1.1TB数据中策略抽样了100GB等量数据集训练了2.6B参数规模的鹏程盘古α模型,模型在16个下游任务中大部分指标优于SOTA模型,对比结果如下:
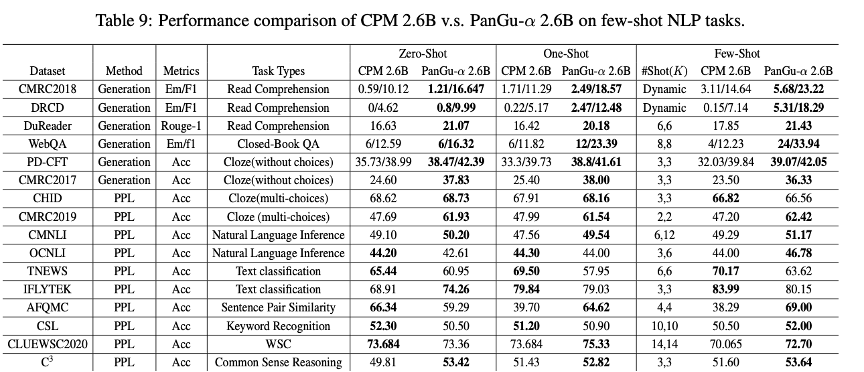
实验结果表明鹏程盘古α-2.6B比悟道文源CPM-2.6B模型具有更强的语言学习能力,尤其是在小样本学习和生成任务方面。在生成任务方面, 鹏程盘古α-2.6B比悟道文源CPM-2.6B性能指标平均提升6.5个百分点。在困惑度PPL任务方面,鹏程盘古α-2.6B在OCNLI、TNEWS和IFLYTEK任务上略弱于文源CPM。这一现象归因于模型使用了更大规模的词表,这使得模型在局部文本变化时对困惑度不敏感。
出色的性能表现基于华为推出的CANN异构计算架构和全场景AI计算框架MindSpore,后者具有全自动混合并行能力。华为云盘古大模型,不仅整合了这两种架构,还融合了三种并行技术:模型并行、数据并行和流水线并行。
在华为“盘古”模型大力发展之时,我国另一超大规模智能模型训练技术体系“悟道”也在全速迭代。

什么是“悟道”
-
悟道·文汇
-
悟道·文澜
-
悟道·文源
-
悟道·文溯
三种超大规模预训练对比

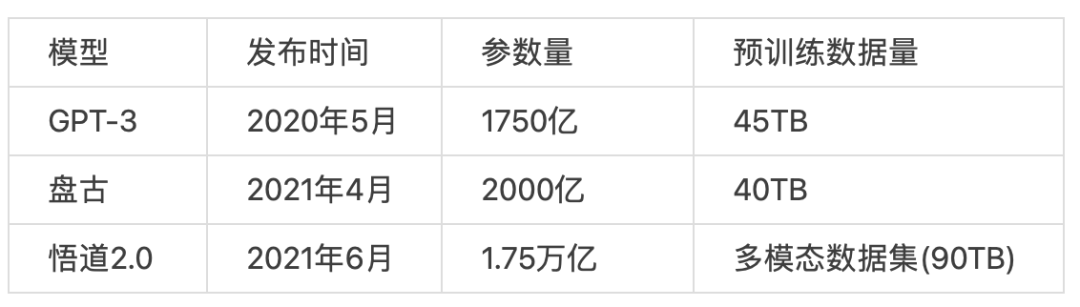
可见,近年来不断出现的各种各样的预训练模型,满足不同领域的需求,也为下游多种任务的处理提供了更多的可能。然而,要想获得超大规模的预训练模型,对于企业的规模、要求和实力均提出了很大的挑战,多数企业并不能独立实现类似前文所述的各类通用预训练模型,比较可行的选择是采纳开源的预训练模型,结合自身领域业务数据的特色,从而形成符合自己的预训练模型,不难看出,这样的选择是明智的,也是较为容易落地的。
企业应用与落地
犀语科技主要服务于泛金融领域,近年来,在银行、证券、保险、资管、监管机构、中介机构及财经媒体等行业相关的业务领域内不断沉淀技术经验,面向实体抽取、文档智能审核、文本比对、制度穿透、泛金融知识图谱等业务场景,为客户不断提高交付标准。因此,拥有泛金融领域的预训练模型显得尤为必要,开源的预训练模型,结合泛金融领域数据,协同整个行业内各类企业,共同训练更加符合金融领域的预训练模型,将成为公司新的技术突破方向,在不断提高预训练效果的前提下,持续为金融机构降低人工智能落地成本,提高客户满意度。


